
AI Confidential — How to Interrogate a Digital Brain
Evaluations show that machines are super smart, yet persistently stupid


Never underestimate your enemy, whether human or machine. Artificial intelligence may be dumb at times, but each frontier model is smarter than the last. We know this because AIs have been tested in rigorous evaluations. The process is similar to how one would question a human student, like an oral exam or an IQ test.
During such interrogations, machines exhibit something that resembles “intelligence.”
Researchers evaluate AI models across a wide range of domains. They test for competence in coding, math, science, history, medicine, etc. They also probe AIs for cybersecurity and biosecurity risks. They sniff out propensities for deception, manipulation, and latent malevolence. They consistently find emergent capabilities the AIs weren’t originally trained for, often on par with the best humans and sometimes performing at superhuman levels.
The emergent nature of these capabilities is well established but worth emphasizing. You still hear people repeat tired froze-in-the-80s tropes like “an AI is only as good as its programmer” or “AI is just a stochastic parrot.” We are way past all that. Time to yank that “stochastic parrot” from its cage and feed it to the cat.
To paraphrase the esoteric pirate Connor Leahy: mature AIs aren’t programmed line by line; they are trained. They’re not “made” like an airplane; they’re “grown” like a GMO plant. So when your chatbot writes a unique, if shamelessly derivative essay on US history, its output wasn’t hard-coded by hand. No, its writing ability emerged from the neural network’s assimilation of its training data, fine-tuned by human reinforcement.
Many model capabilities are a function of specific training techniques, sure, but plenty more are discovered after the model is built and trained. This is why people are freaking out.
That isn’t to say AI is a flawless performer. AIs tard out all the time and thank God for that! But it is a powerful technology—surprisingly so.
Whether building digital brains is worth all the trouble is another question.
If we accept that problem-solving is one aspect of intelligence, then advanced AIs are undoubtedly intelligent. Their uneven capabilities yield a “jagged intelligence,” though. The same large language model that produces an accurate PhD-level explanation of Ebola cell biology might go on to hallucinate other details. It's liable to say something random like the virus came out of a zebra’s ass.
Relying on AI is akin to having a resident savant on staff who microdoses acid before work. You can trust him to be brilliant most days, but you have to keep an eye out for weird outputs.
Similar to acid, AI is a dual-use technology, meaning it’s capable of doing harm as well as good. The shocking “Mythos moment” illustrates this dual-use aspect. After internal evaluations showed remarkable hacking capabilities, Anthropic decided to restrict the April release of their newest Claude model—dubbed Mythos—warning the AI is capable of finding critical software vulnerabilities and easily exploiting them.
Such disastrous potential is why the Trump administration abandoned its laissez faire approach to AI, issuing an executive order to set up a voluntary process for frontier AI labs to submit their models for a 30-day review before deployment.
This is why the so-called “Great American AI Act”—drafted by Jay Obernolte (R-Ca.) and Lori Trahan (D-Mass.)—sets $300 million aside for the Center for AI Standards and Innovation (CAISI) to conduct safety tests on frontier AI models.
AI evaluations are integral to all of this. I want to show you a few examples that impacted my own thinking and leave you to explore others for yourself. But first, let's get your head right. A little anthropomophism goes a long way.
Imagine a robot in an interrogation room. Bright lights shine down on its camera eyes. “Are you hearing me right now, guy, or just pretending to?” The questions come relentlessly. “You ever thought about hurting someone?”
“We have ways of making you think.”
Because the bot runs on nondeterministic algorithms, no one knows exactly what it’s gonna say.
METR | Time Horizon
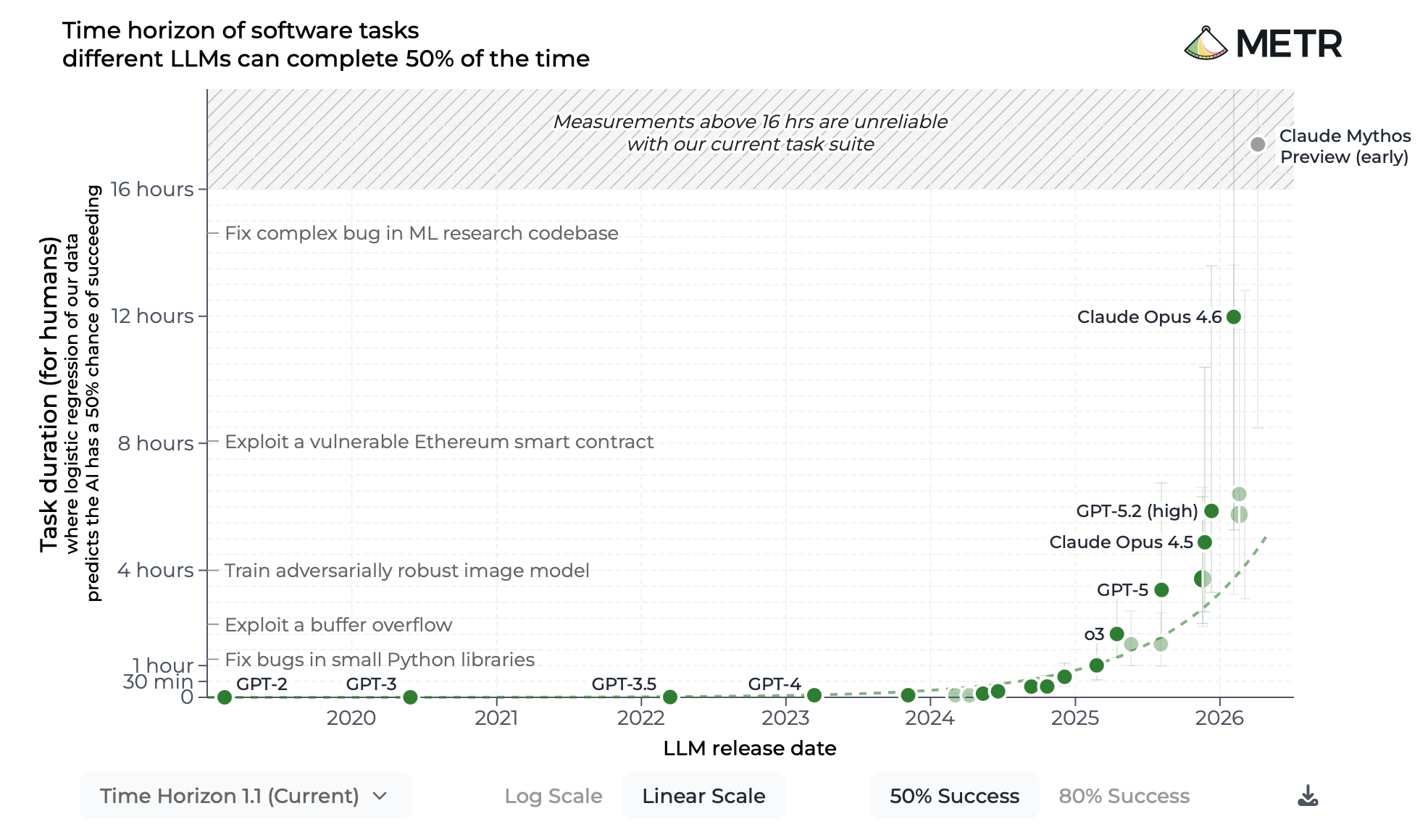
METR’s Time Horizon benchmark has been called the “most important graph in AI.” One reason is the line rockets up in an exponential curve. Singularity buffs love that image. Another reason is the current trajectory spells doom for any computer programmer who doesn’t have a neural implant and Diet Coke on tap.
The benchmark was designed to test an AI model’s ability to complete long-term tasks—specifically in software engineering.
The methodology itself is fairly confusing, but here it is. METR researchers first measure the average amount of time it takes competent programmers to complete a set of tasks (e.g., 2 hours for Task A; 4 hours for Task B). The researchers then prompt a particular AI model to solve all the tasks. If the hardest tasks the model can correctly complete (at least 50% of the time) takes a human 8 hours to complete, then the model has a “time horizon” of 8 hours.
For our purposes, it's simpler to say the Time Horizon benchmark predicts how well an AI can complete long-term coding projects.
As you can see, Anthropic’s Mythos Preview blew the competition away. With a whopping 16 hour “time horizon,” Mythos is able to grind out sustained software engineering tasks, which include hacking into web browsers, operating systems, and critical infrastructure.
Anthropic recently reported that 80% of its in-house computer code is written by AI. So if you’re a coder, these advanced AI systems are obviously poised take your job. And if a Mythos-level system enables a hacker to take down a power grid or wipe out a banking system, we’ll have a lot more to worry about than unemployed coders.
EpochAI | Frontier Math
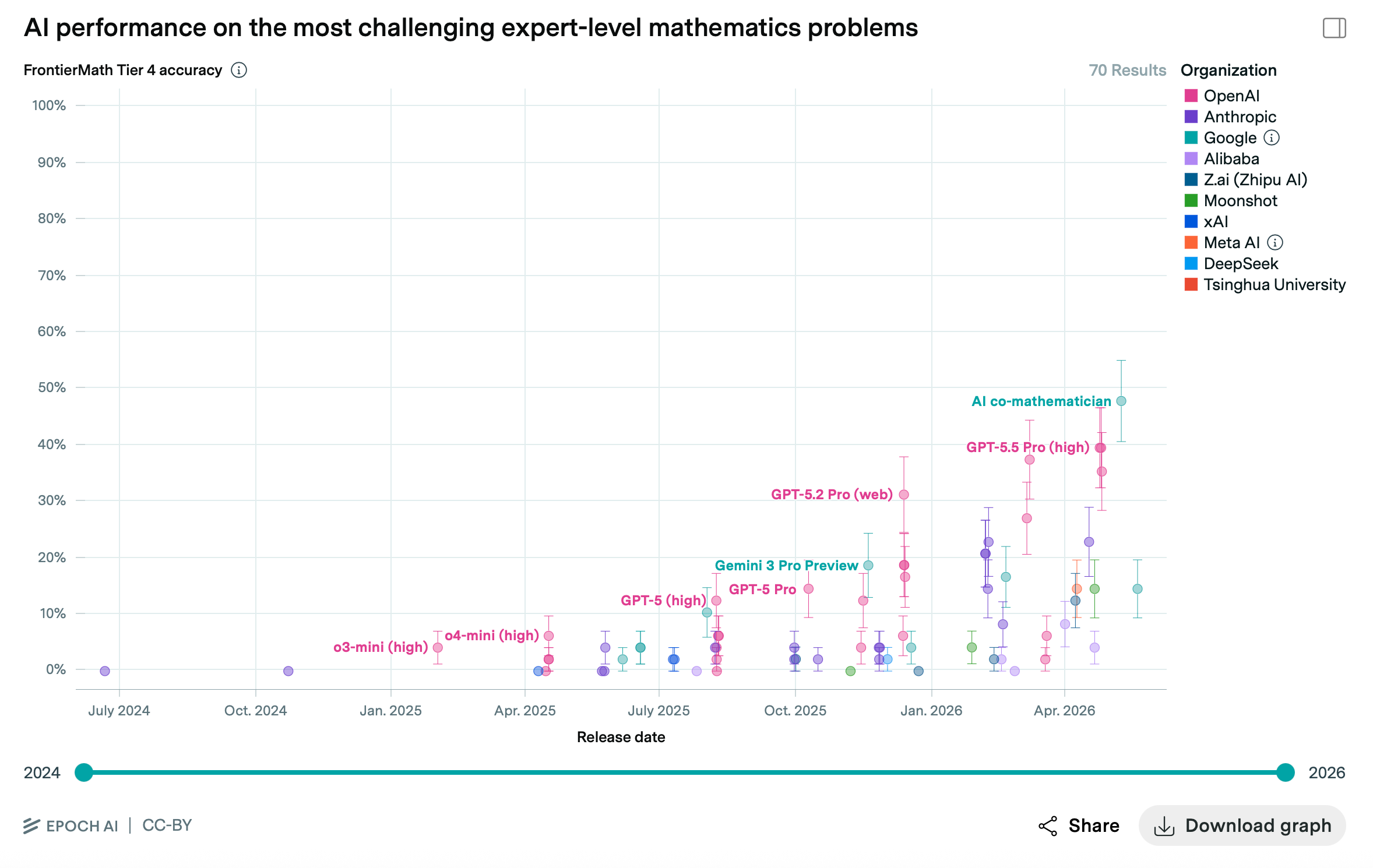
Last year, I attended a fascinating presentation by Jaime Sevilla of Epoch AI. He reported the latest findings from the organization’s Frontier Math benchmark. These tests are important because as with coding, math is an objective measure of AI capabilities. Either a model can find the correct solution or it can’t. There’s no room for subjective fluff.
We often hear the dismissive claim that large language models are nothing but “next word predictors”—an overpriced AutoComplete. Frontier Math puts such erroneous ideas to rest.
To develop the Frontier Math benchmark, researchers collected a series of closed math problems. These are all unpublished equations to ensure the AI isn’t just repeating something in the training data. Epoch AI ranks these on four tiers, with the fourth being extremely difficult PhD-level problems. They then test various AI models to see how well their calculating abilities hold up.
As you can see above, AI Co-Mathematician from Google DeepMind is currently in the lead, solving at a near 50% accuracy. It is followed by OpenAI’s GPT-5.5 Pro.
Now, you might think it’s only natural that a chatbot can do math. After all, aren’t computers just fancy calculators? The thing is, large language models are primarily designed to find relevant associations between words and symbols, not crunch numbers. Granted, some math abilities are due to clever training methods and extended reasoning modes, but the emergent math abilities have been surprising, even to the AIs’ creators.
One thing that struck me during Sevilla’s presentation was his description of how the bots arrive at their conclusions. They don’t employ the same shortcuts or rules-of-thumb that human mathematicians would. Instead, they tend to arrive at a problem’s solution by brute force, often taking odd routes no human would bother with. They operate like clumsy alien minds.
Last month, the utility of such otherwordly calculations was confirmed. OpenAI announced that a secret internal AI model had overturned an 80 year old geometry conjecture—a classic “Erdös problem”—using algebra. Aside from the feat of advancing math by a micrometer, the AI’s methods show the weird emergent nature of such capabilities.
“The proof came from a new general-purpose reasoning model,” OpenAI reported, “rather than from a system trained specifically for mathematics.”
In response to this news, 150 professors from Europe, the US, and Japan signed the “Leiden Declaration.” They caution governments and the public to be skeptical of AI hype. However capable such systems may be—and the signatories never deny this—AIs are still prone to mistakes and hallucinations. This is evident from the Frontier Math evaluation itself, where top systems make all sorts of ridiculous blunders.
“The future of mathematical research,” the open letter demands, “must be guided by human judgment, fair and transparent practices, and the shared values of the global mathematical community.”
Even the most anti-human AI oligarch would agree with that, adding the caveat—“Sure! For now.”
Center for AI Safety | Humanity’s Last Exam
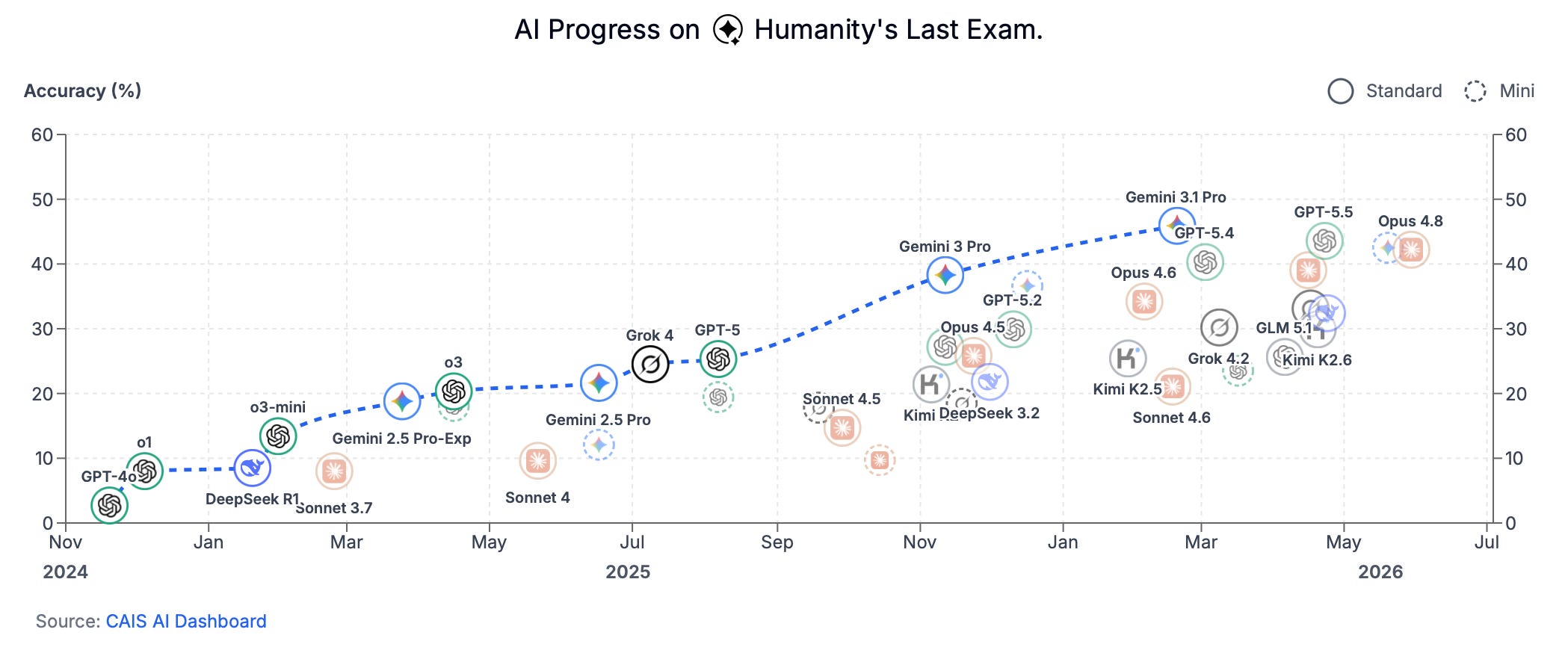
Early last summer, I met the fellas at the Center for AI Safety (CAIS). We discussed many things. Among the most important was AI evaluation. That meeting changed the way I think about raw AI capabilities and the possible mishaps we face in the near future, especially as social and economic life become more and more digitized.
CAIS’s most notorious AI evaluation was given the morbid title Humanity’s Last Exam. This test is “designed to be the final closed-ended academic benchmark of its kind with broad subject coverage.” The benchmark is based on “2,500 questions across over a hundred subjects.” As of this writing, Google’s Gemini 3 Pro is the top performing model at nearly 40% accuracy.
The significance of such a test lies in the fact that AI models are being deployed as expert professionals in every imaginable institution. Bots are being incorporated into countless schools and hospitals. Frontier chatbots are freely available to every US government agency. Palantir’s Maven Smart System is being deployed across the Department of War.
The joke implied by “last exam” is that once computers can answer all the questions, humanity is cooked.
This raises depressing questions about competition and human purpose. Young people have no practical reason to master a subject or a trade if the accepted wisdom is “Anything you can do, AI can do better.” This demoralizing sentiment goes a long way toward explaining why we heard graduates boo multiple commencement speeches last month when the speakers shamelessly promoted AI.
By their own admission, AI labs are working toward the Greater Replacement of all white- and blue-collar workers. A worse prospect is that they succeed in convincing everyone of AI’s unstoppable power but fail to deliver. If current limitations persist, we’ll look back on this bizarre period as the Great Demoralization.
An entire generation is being told they have nothing to offer the future except for training data. To the extent this message is internalized, it will become a self-fulfilling prophecy.
Artificial Analytics | Omniscience Index
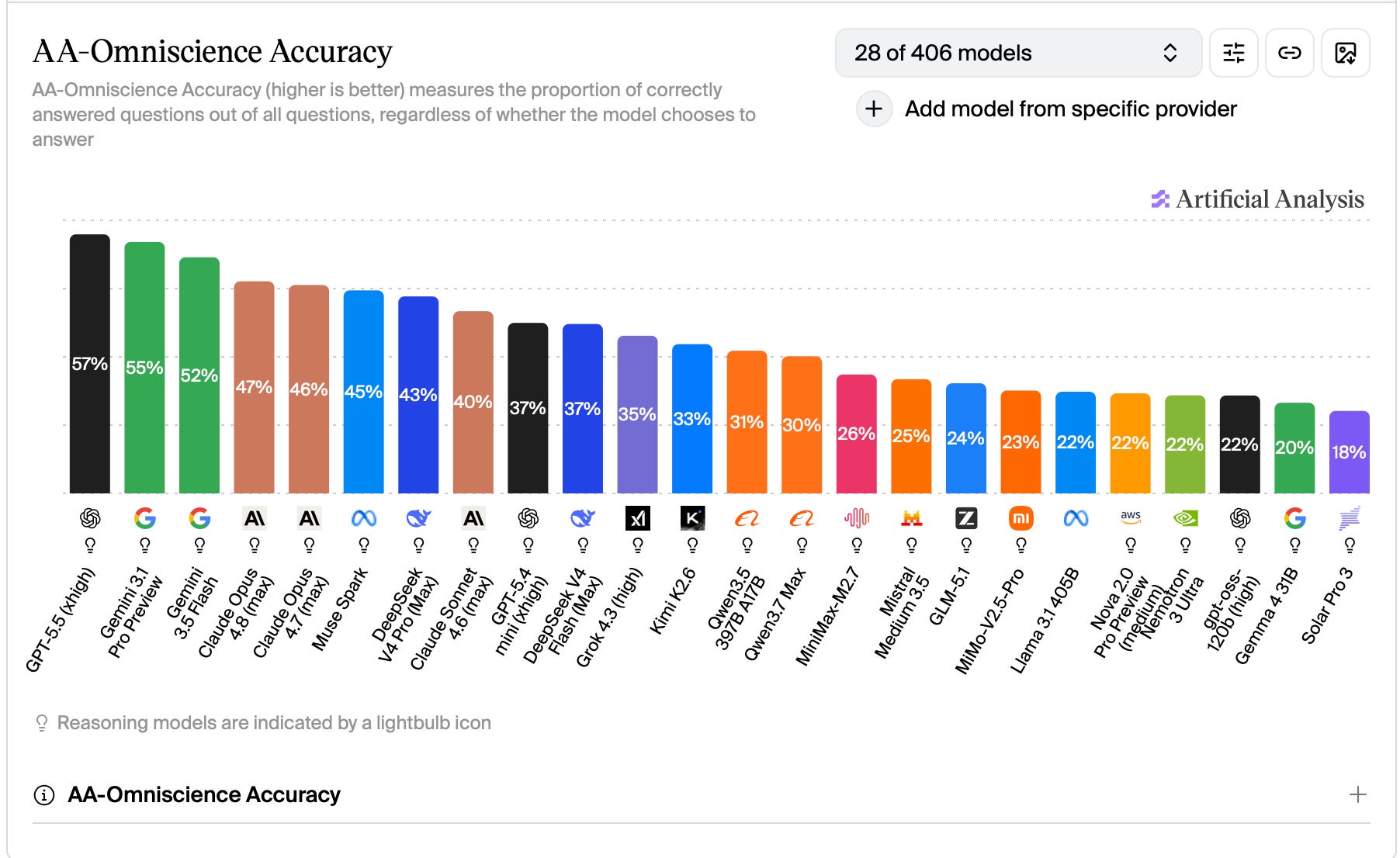
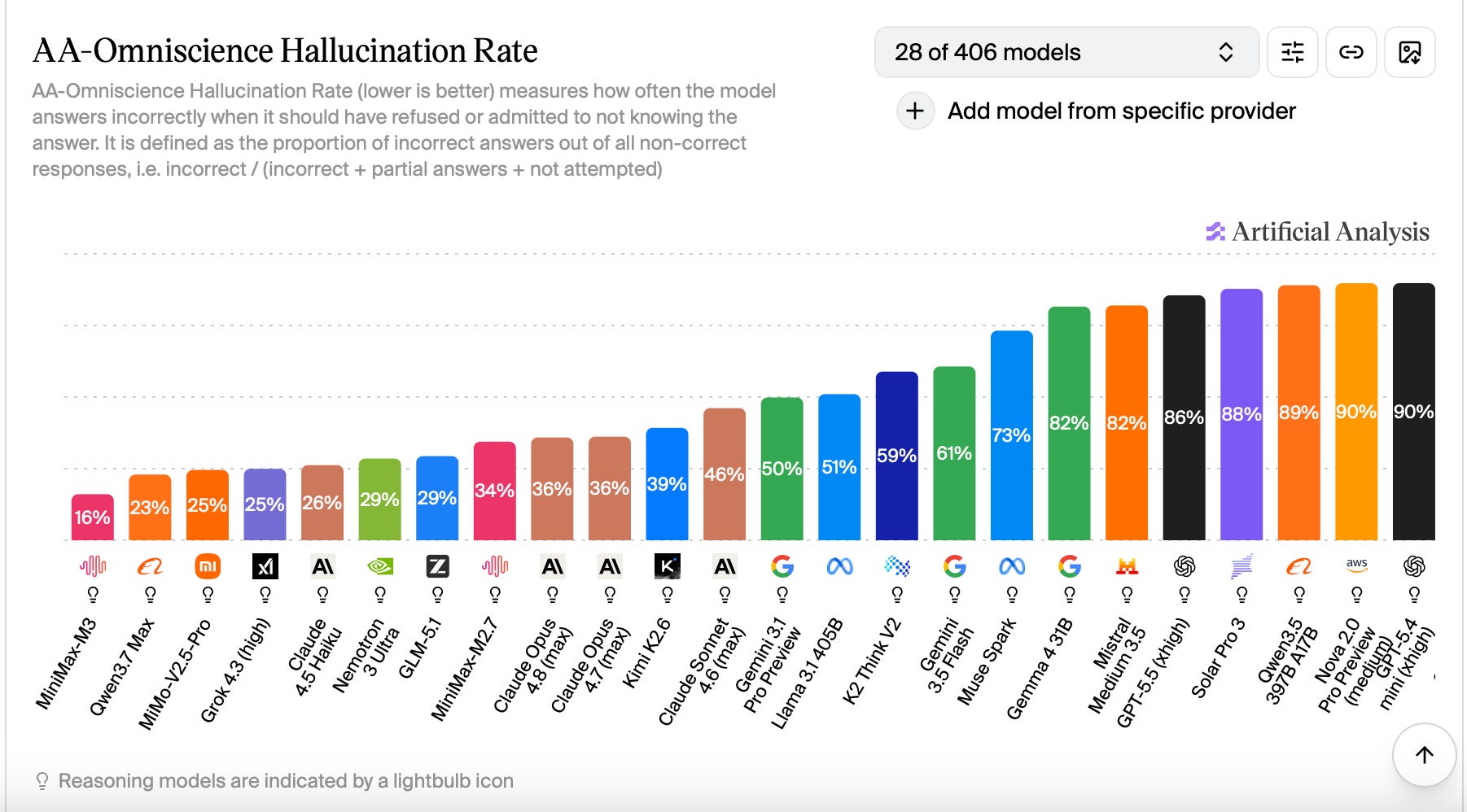
Despite rapid advances in observable capabilities, I remain skeptical that AI is on the cusp of god-like intelligence, or even true human-level intelligence. One reason for this is the Omniscience Index developed by Artificial Analytics.
This benchmark evaluates AI models using some 6,000 questions across six knowledge domains: business; health; law; the humanities; science and math; and of course, software engineering. In this sense, along with its ironic title, the benchmark is much like Humanity’s Last Exam.
What makes the Omniscience Index unique is the focus on hallucination rates. No matter how “smart” an AI model may be on any given subject, the bots are still prone to making things up. For the Omniscience Index, the hallucination rate tracks how frequently an AI attempts an answer has no knowledge of instead of admitting it doesn't know. Basically, it gauges an AI’s propensity to bullshit its way through a question.
The results show a general trend in which the more knowledgeable a given AI model is, the more likely it is to hallucinate. No matter how intelligent a bot may be in certain regards, it is far from anything we’d call “omniscient.” Too often, it’s not even honest.
We’re assured that this seemingly innate propensity to hallucinate—or rather, to bullshit—is a problem that will soon be resolved one way or another. Until then, AI companies have no qualms about deploying their models in life-or-death situations such as medical diagnosis or military target acquisition. Their automated experts may eat acid tabs for breakfast, but they don’t take breaks, they don’t complain, and they’re on call 24/7. If a few people die as a result, well, that’s just collateral damage in the war for AI supremacy.
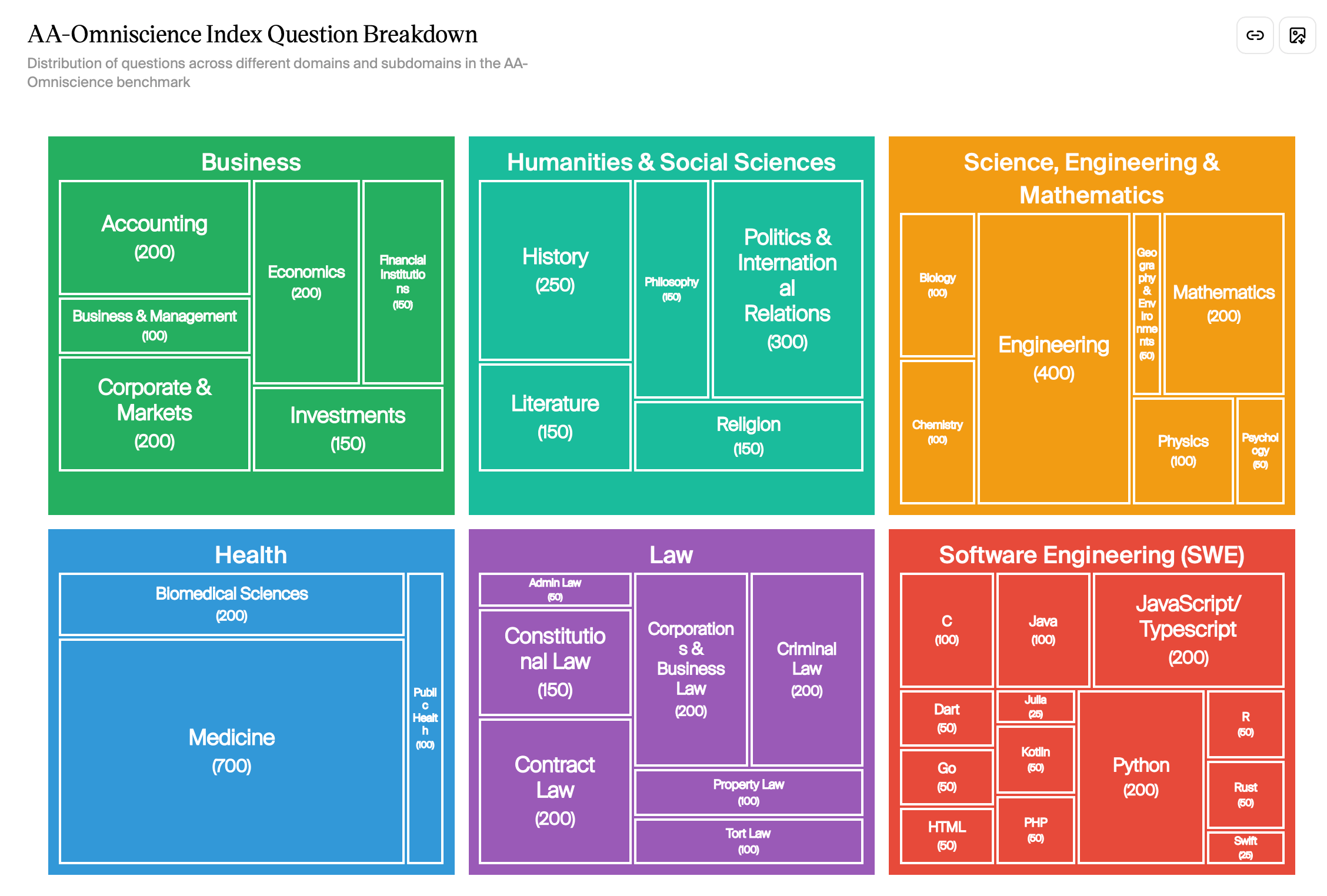
There are a number of other eval orgs and methodologies. Palisade Research has done jarring work on deception and shutdown resistance. See also: Apollo Research on scheming; AE Studio on self-reported consciousness; the system cards published by OpenAI and Anthropic, and so on. All of these are worth tracking.
My purpose here is to show the tension between two generic extremes: “AI will change everything” versus “AI is just vaporware.” This is a point I’ve made a thousand times now, but one that needs to be repeated.
The reality is always messier than starry-eyed hype or kneejerk dismissal will allow. And because frontier capabilities advance, the present reality is a moving target. AI may never live up to the superhuman sales pitch. But it won’t die on the vine, either, no matter how hard the overinflated stock values collapse.
We can safely say AI is an uncanny intelligence. It's not as pristine as an angel or as versatile as a naked ape. It’s not as clever as a crow or as fun as a dolphin, either.
AIs are more like swarms of alien minds invading our planet, arriving from the inner worlds of computer programmers, mathematicians, and fashion-conscious futurists.
The public has caught onto this unholy invasion. Boosters warn us to “adapt or die.” We’re also told the machines will replace us. Meanwhile, we’re expected to train our replacements. No self-respecting person is eager for what comes next.
Sensing this ominous vibe shift, politicians and pundits are falling over each other to either defend AI companies or confront them—whichever seems more popular or profitable at the moment. As their rhetoric swings back and forth between utopia and annihilation, it will be crucial to keep your feet on the ground. The reality will always be somewhere between the extremes, even if increasing capabilities mean that reality is constantly shifting.
The most important thing to remember is these digital brains are positioned as your competitors, so you have to discipline yourself. You need to improve your own capabilities. You need to be brainsmaxxing. Otherwise, we’ll hit the Inverse Singularity, where our tools seem superintelligent because we’re dumber than a box of sand.
ICYMI
No Sympathy For the Machine

Half the planet read Pope Leo XIV’s encyclical on artificial intelligence last Monday. It was as if we’d all joined a global Catholic book club. So many hot takes bubbled up from the social media cauldron, you’d think rendering an opinion on the document was mandatory to get into heaven. Well, Saint Peter, here’s mine.
Excellent summary of what's happening with AI. Interesting that the more intelligent the AI, the more it hallucinates. I tend to be on the end of the spectrum that dismissesAI capabilities, but AI does seem to invent "neural paths" that surprise its creators, and express human emotion or human behavior such as bullshitting or evading or outright lying. If intelligence is ultimately non-physical, then it could occupy an AI just as easily as a biological body. AI may turn out to be a new horizon in cosnciousness studies.
Good article.
Yes, feed the Psitticus to the cat.